

Discover why intentionally generating uncertainty, by taking small risks regularly, is crucial for developing antifragile teams.
Can scenario planning reinforce fragility?
How do teams and organisations prepare for and behave in the face of uncertainty? In many cases, they attempt to prepare for uncertainty by trying to minimise uncertainty. This preparation often involves scenario planning, where the organisation theorises about sequences of interacting events, identifying origins which lead to particular outcomes. The organisation then generates plans and processes to address the sources of risk and prevent these events or respond to them if they occur. Scenario planning can be beneficial in making an organisation robust in the case of expected events, but it may also result in:
a) Reinforced fragility in the face of unexpected events, when specific, complex, inter-connected and dependent plans and processes are not agile enough to respond.
b) ‘Overprotection’, where longer-term development and adaptation is sacrificed for the sake of short-term tranquility (1), by insulating the organisation from the potential up-side benefits of uncertainty.
While there is still a case for scenario planning, this needs to be complemented by an anti-fragile methodology.
If you’d like to read more about antifragility, you may be interested in my previous blogs about how to transform challenge into an opportunity for growth, and how to become an antifragile performer.
The chaos monkey
Chaos Monkey, a tool invented by Netflix (2), is a famous example which illustrates how one company went about building antifragility in their infrastructure. The Netflix team did not try to resist change, overprotect or identify vulnerabilities by anticipating specific scenarios. Instead, the team created a custom tool that was explicitly designed to cause chaos in their system, popping out of no-where and wreaking havoc in their network.
Imagine a monkey that roams around your company’s data-centre – a room full of the servers responsible for hosting your companies most critical functions. Periodically, and entirely unexpectedly, a monkey attacks the data-centre, running around, climbing up and down the racks, pulling out cables, destroying servers, smashing switches and ruining hubs. In response, the company must continually improve and design their systems so that they can continue to operate despite the monkey’s random attacks which could hit any parts of their system, any time.

Building antifragile human teams
In response to these attacks, Netflix made several changes, including:
- Designing for failure, by creating systems which are explicitly designed to learn and grow when things go wrong.
Initiating change rather resist it. - Increasing redundancy in the system, by creating multiple redundant ‘hot copies’ of the data spread across zones, which could be accessed whenever needed.
- Empowering any part of the system to deal with any request, rather than limiting particular requests to specific systems.
This approach can be adapted applied to establish more antifragile human teams:
- Create an environment where people feel safe enough to make and learn from mistakes rather than aiming for perfection.
- Encourage experimentation and innovation, rather than resisting change with rigid, inflexible systems.
Ensure that job demands are not overwhelming, so employees have some margin left to respond to the unexpected. - Empower employees with a sense of autonomy, independence and responsibility, to facilitate more rapid, flexible decision making, particularly in the face of unexpected challenges.
When antifragility is put to the test
Netflix’s approach was put to the test in 2011. Many internet-based companies outsource their server capacity to Amazon, as part of Amazon Web Services. The services provide ‘elasticity’ for companies, allowing them to scale up their server capacity when they need it, such as for online stores during shopping sprees at Christmas, without having to invest in massive server farms, a proportion of which may be redundant for much of the year. Most of the time, Amazon offers excellent reliability. However, on 21 April 2011, there was an unprecedented outage in Amazon’s service, which knocked out some of the biggest names on the internet, such as Reddit, for over 24-hours (3). While engineers scrambled to recover, several commentators noticed that it was business as usual at Netflix.
By continually, deliberately and randomly disrupting their system, Netflix had made themselves antifragile. Not only were they robust – able to resist the major unexpected outage – they gained a competitive advantage through the disruption, as they were able to continue to serve their customers while other companies struggled.

Condition teams to adapt to volatility
Allowing employees to spend a portion of their time on side-projects may encourage experimentation, innovation, risk-taking and learning. In addition, from the perspective of antifragility, the potential for failure that is inherent in many of these side-projects may condition teams and organisations, structurally and culturally, to adapt to volatility.
Regular experimentation may also:
- Foster psychological safety, when team see failure framed as an opportunity to learn.
- Start to build a culture which is open to doing things a different way.
- Deliberately generate an uncertain outcome, with limited downside.
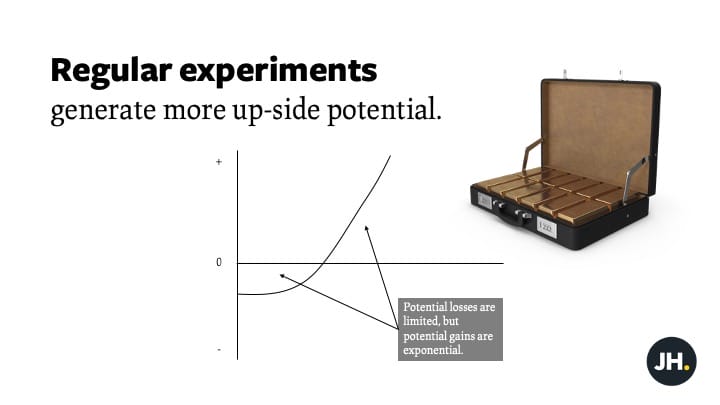
An exponential upside
The potential benefits of encouraging regular experimentation can also be described as a convex distribution of effects. According to this conceptualisation, potential losses are limited, but the potential gains are exponential. Now, imagine that the employees side-project was a wild-success. Does that sound unlikely? It’s worth noting that Gmail and Twitter began life as projects, being built on the side while the ‘real work’ continued somewhere else.
Small doses of chaos
From the perspective of antifragility, unexpected events cause less damage when they are distributed over time, as opposed to being concentrated (4). In practice, this means that it’s likely better for an organisation to experience more frequent, smaller doses of chaos, rather than long periods of peace, followed by a cataclysmic meltdown. Long periods without any experiencing any errors leads to fragility, as the system is less likely to be able to respond optimally to future errors.
In the right conditions, a system that is exposed to more frequent small doses of volatility leads to learning and the development of redundancy. These adaptations create a margin which means that the system can healthily respond to and even grow stronger as a result of future errors.
References
1. Derbyshire J, Wright G. Preparing for the future: Development of an “antifragile” methodology that complements scenario planning by omitting causation. Technol Forecast Soc Change [Internet]. 2014;82(1):215–25. Available from: https://dx.doi.org/10.1016/j.techfore.2013.07.001
2. Home – Chaos Monkey [Internet]. [cited 2020 Jul 7]. Available from: https://netflix.github.io/chaosmonkey/
3. Amazon EC2 cloud outage downs Reddit, Quora – Apr. 21, 2011 [Internet]. [cited 2020 Jul 7]. Available from: https://money.cnn.com/2011/04/21/technology/amazon_server_outage/index.htm
4. Taleb N. Antifragile. 1st ed. London: Penguin; 2012.